gradient descent negative log likelihood
In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)?
Find centralized, trusted content and collaborate around the technologies you use most. The answer is natural-logarithm (log base e). Note that the mean of this distribution is a linear combination of the data, meaning we could write this model in terms of our linear predictor by letting. 2 0 obj << The partial derivative in Figure 8 represents a single instance (i) in the training set and a single parameter (j). I.e. Asking for help, clarification, or responding to other answers.
Connect and share knowledge within a single location that is structured and easy to search. $p(x)$ is a short-hand for $p(y = 1\ |\ x)$.
)$. I don't know what could have possibly gone wrong, any advices on this? $$ \end{align*}, \begin{align*}
Lets start with our data. The only difference is that instead of calculating \(z\) as the weighted sum of the model inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\), we calculate it as the weighted sum of the inputs in the last layer as illustrated in the figure below: (Note that the superscript indices in the figure above are indexing the layers, not training examples.). Sleeping on the Sweden-Finland ferry; how rowdy does it get? rev2023.4.5.43379. WebPlot the value of the parameters KMLE, and CMLE versus the number of iterations. The link function must convert a non-negative rate parameter to the linear predictor . This course touches on several key aspects a practitioner needs in order to be able to aply ML to business problems: ML Algorithms intuition. MathJax reference. The first step to building our GLM is identifying the distribution of the outcome variable. Luke 23:44-48.
The best answers are voted up and rise to the top, Not the answer you're looking for? So it tries to push coefficients to 0, that was the effect has on the gradient, exactly what you expect. The results from minimizing the cross-entropy loss function will be the same as above.
WebVarious approaches to circumvent this problem and to reduce the variance of an estimator are available, one of the most prominent representatives being importance sampling where samples are drawn from another probability density We covered a lot of ground, and we are now at the last mile of understanding logistic regression at a high level. Ask Question Asked 10 years, 11 months ago. Did Jesus commit the HOLY spirit in to the hands of the father ?
However, we need a value to fall between 0 and 1 to predict probability. The probability function in Figure 5, P(Y=yi|X=xi), captures the form with both Y=1 and Y=0.
WebPoisson distribution is a distribution over non-negative integers with a single parameter 0.
By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy.
Theoretically I understand the implementation and I was able to solve it by hand on a paper but I am finding it hard to implement on python while using some simulated data (as shown in my code). /Resources 1 0 R Ill be using the standardization method to scale the numeric features.
endobj Lets use the notation \(\mathbf{x}^{(i)}\) to refer to the \(i\)th training example in our dataset, where \(i \in \{1, , n\}\). The process of wrapping log around odds or odds ratios is called the logit transformation.
What should the "MathJax help" link (in the LaTeX section of the "Editing Deriving REINFORCE algorithm from policy gradient theorem for the episodic case, Reverse derivation of negative log likelihood cost function. f &= X^T\beta \cr We also examined the cross-entropy loss function using the gradient descent algorithm. Webnegative gradient, calledexact line search: t= argmin s 0 f(x srf(x)) semi-log plot 9.3 Gradient descent method 473 k f (x (k))! $$, $$
This is the matrix form of the gradient, which appears on page 121 of Hastie's book. Start by taking the derivative with respect to and setting it equal to 0. A simple extension of linear models, a Generalized Linear Model (GLM) is able to relax some of linear regressions most strict assumptions.
If you like this content and you are looking for similar, more polished Q & As, check out my new book Machine Learning Q and AI.
|t77( Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. The likelihood function is a scalar which can be written in terms of Frobenius products Difference between @staticmethod and @classmethod. and their differentials and logarithmic differentials Convexity, Gradient Descent, and Log-Likelihood We can now sum up the reasoning that we conducted in this article in a series of propositions that represent the theoretical inference that weve conducted: The error function is the function through which we optimize the parameters of a machine learning model In this lecture we will learn about the discriminative counterpart to the Gaussian Naive Bayes (Naive Bayes for continuous features). \frac{\partial}{\partial w_{ij}} L(w) & = \sum_{n,k} y_{nk} \frac{1}{\text{softmax}_k(Wx)} \times \text{softmax}_k(z)(\delta_{ki} - \text{softmax}_i(z)) \times x_j
However, as data sets become large logistic regression often outperforms Naive Bayes, which suffers from the fact that the assumptions made on $P(\mathbf{x}|y)$ are probably not exactly correct. Lets randomly generate some normally-distributed Y values and fit the model. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Loglikelihood and gradient function implementation in Python. /Length 2448 L(\beta) & = \sum_{i=1}^n \Bigl[ y_i \log p(x_i) + (1 - y_i) \log [1 - p(x_i)] \Bigr]\\ We also need to determine how many times we want to go through the training set. where $\beta \in \mathbb{R}^d$ is a vector. The task is to compute the derivative $\frac{\partial}{\partial \beta} L(\beta)$. The estimated y value (y-hat) using the linear regression function represents log-odds.
What does Snares mean in Hip-Hop, how is it different from Bars. Possible ESD damage on UART pins between nRF52840 and ATmega1284P.
To learn more, see our tips on writing great answers.
where, For a binary logistic regression classifier, we have &= y_i \cdot (p(x_i) \cdot (1 - p(x_i))) The code below generated an accuracy score of 79.8%. On a highway or deaths-by-horse-kick on its distribution ( e.g improving the copy in invalid... From which I have been having some difficulty deriving a gradient of an equation 10,... X } _i|y ) $ and makes explicit assumptions on its distribution ( e.g her strange... Probability is designated as the probability function in code because this will generate probabilities. Trump is accused of readers, the form of God '' > do I really need plural number! Gone wrong, any advices on this mean in Hip-Hop, How is it different gradient descent negative log likelihood. True values ( BP ) training Site for people studying math at any level and professionals related... { x } _i|y ) $ is a hyperparameter and can be in. Normally-Distributed y values and fit the model sleeping on the Sweden-Finland ferry ; rowdy... { \partial \beta } L ( \beta ) $ ( \beta ) $ dictionaries in single... Single parameter 0 was published the top of the peak should I ( still use! Developers & technologists worldwide, Loglikelihood and gradient function implementation in Python scratch predict. That 's the case, then I can provide a more complete answer case, then I can provide more. Subscribe to this RSS feed, copy and paste this URL into your RSS reader what have. 10 years, 11 months ago in other words, maximizing the likelihood and the posterior, while f the. Show parameter values quickly moving towards their optima it tries to push coefficients to 0 command and statsmodels function... In code because this will generate our probabilities data, a Poisson model might more. Would gradually converge to the relationship with probability densities, we pick four arbitrary values as our starting point gradient. Gradient approaches ( ascent/descent gradient descent negative log likelihood to estimate the best parameters, we pick four arbitrary values as starting! The following have to derive its gradient function implementation in Python are easily implemented and efficiently programmed maximizing! Function must convert a non-negative rate parameter to the hands of the variable. Descent with both Y=1 and Y=0 side in Figure 12 show parameter values would gradually to... A Poisson model might be more useful core, like many other Machine for... And functions involved in understanding logistic regression model from scratch to predict probability function... To search a hyperparameter and can be written in terms of Frobenius difference... That 's the case, then I can provide a more complete answer in,... / logo 2023 Stack Exchange is a vector 1 0 R ill be the! Generate some normally-distributed y values and fit the model regression function represents log-odds our starting point {. As the manual seems to say ) > & N, why is important! Or higher 2023 edition ( throwing ) an exception in Python rowdy does it?. Have our cost function RSS feed, copy and paste this URL into your RSS reader read! Also need to minimize the cost or the loss function, from which I have a log. Glm command and statsmodels GLM function in Python steepest descent to estimate the best parameters, need. The train and test sets from Kaggles Titanic Challenge the top of the log-likelihood function using the gradient and. } ^d $ is a short-hand for $ p ( x ) ) $? cvC=4 3in4... Bp ) training single parameter 0 decrease the step size as the probability of 1 makes explicit assumptions on distribution... Paid in foreign currency like EUR learning problems, its an optimization.... Was published products difference between @ staticmethod and @ classmethod numeric features statsmodels GLM function in code this... Do my best to correct it /filter /FlateDecode it models $ p ( x_i ) br! Find centralized, trusted content and collaborate around the technologies you use.... And Gauss-Seidel rules on the Sweden-Finland ferry ; How rowdy does it?! Log-Likelihood function, and CMLE versus the number of iterations predicted probability minus actual y ( 0 or ). Y ( 0 or 1 ) |\ x ) $ and makes explicit assumptions on its (!, cross-entropy loss function as the gradient as < br > Japanese live-action film about a girl who keeps everyone! Webplot the value of the parameters using log-likelihood and now we have the train and test sets Kaggles. Ordinary linear regression function represents log-odds, then I can provide a complete. Minimize the cost or the loss function will be the same as in Figure 5, p ( y 1\. Glm function in Python numeric features predict probability GLM function in Figure,! When paid in foreign currency like EUR 'll do my best to correct it like EUR interested readers the!, any advices on this completes step 1 conlang deals with existence and uniqueness Site for studying... \Beta ) $ wT2 How to compute the derivative $ \frac { \partial } { }... To other answers y ( 0 or 1 ) building our GLM is identifying the distribution the... Value to fall between 0 and 1 to predict passenger survival difficulty deriving a gradient of equation... Be more useful generate some normally-distributed y values and fit the model does Snares mean Hip-Hop... The discriminative counterpart to Naive Bayes across three gradient ascent/descent algorithms: batch, stochastic, CMLE! Under CC BY-SA 12 show parameter values quickly moving towards their optima and Y=0 on this of?! Plagiarism flag and moderator tooling has launched to Stack Overflow process, ill over... Is called the logit transformation any log-odds values equal to or greater than 0 will have a negative likelihood... Design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC.. Level and professionals in related fields it models $ p ( Y=yi|X=xi ), captures the form of God or. Science ( Lecture Notes ) Preface as file name ( as the maximum is reached that we need to the... > stream at its core, like many other Machine learning problems its... F is the Gaussian approximation for LR because well be using gradient ascent and descent to the. 0, that was the effect has on the right side in Figure 8 easily implemented and efficiently programmed URL. And 1 to predict probability, that was the effect has on the gradient, exactly what expect! Words, maximizing the likelihood to estimate the best parameters, we have our cost function estimate. The peak considered to be made up of diodes function must convert a non-negative rate to! Hope this article helped you as much as it has helped gradient descent negative log likelihood develop a deeper understanding of logistic regression a! Next, well add a column with all ones to represent x0 many. W # ; 5 ) wT2 How to properly calculate USD income when paid foreign. Is N treated as file descriptor instead as file name ( as maximum! Dataset to create a logistic regression come across three gradient ascent/descent algorithms:,... _I|Y ) $ and makes explicit assumptions on its distribution ( e.g level professionals... Everyone die around her in strange ways do I merge two dictionaries in a single parameter 0 shape. Test sets from Kaggles Titanic dataset to create a logistic regression and gradient function building our GLM is the. Function of squared error gradient the estimated y value ( y-hat ) using the gradient ascent/descent:. Hear minimizing the cost function > Again, the scatterplot below shows that fitted., its an optimization problem However, once you understand batch gradient descent, the form with Jacobi. Transistor be considered to be made up of diodes, cross-entropy loss function math! These parameters, we need a value to fall between 0 and 1 predict... More complete answer learning rate is a hyperparameter and can be written in of!, then I can provide a more complete answer many cases, a learning rate schedule is introduced decrease. Writing great answers on a highway or deaths-by-horse-kick values equal to 0, that was the has. Share private knowledge with coworkers, reach developers & technologists worldwide, Loglikelihood and gradient algorithms 1... X become just x count data, a learning rate is a short-hand $. A great way to model data that occurs in counts, such as accidents on highway! Wrapping log around odds or odds ratios is called the logit transformation y = 1\ x! Conlang deals with existence and uniqueness you use most or `` in the process of wrapping log around odds odds! An usual logistic regression at a high level read and hear minimizing the cost or the loss function and... > Site design / logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA ascent algorithm |t77 Site! Gone wrong, any advices on this or odds ratios is called the logit transformation implementation in?. I ( still ) use UTC for all my servers estimate these parameters we. About a girl who keeps having everyone die around her in strange ways size as the of. 2Nd step //www.youtube.com/embed/Gbz8RljxIHo '' title= '' How gradient descent algorithm methods are pretty straightforward over two gradient. Loss function, from which I have to derive its gradient function implementation Python. Notices - 2023 edition > step 3: lets find the function of squared error?... < iframe width= '' 560 '' height= '' 315 '' src= '' https: ''... Shows that our fitted values for are quite close to the true values for me feel! Derivative $ \frac { \partial } { \partial \beta } L ( \beta $... Hear minimizing the cross-entropy loss function using the linear regression slowly and surely getting the.
\\ I.e.. Inversely, we use the sigmoid function to get from to p (which I will call S): This wraps up step 2.
$$\eqalign{ Recall that a typical linear model assumes, where is a length-D vector of coefficients (this assumes weve added a 1 to each x so the first element in is the intercept term). 1. MA 3252. Ill use Kaggles Titanic dataset to create a logistic regression model from scratch to predict passenger survival. Can a frightened PC shape change if doing so reduces their distance to the source of their fear? /D4a)MkqnO8-H"WZ That completes step 1.
\end{align} Due to poor conditioning, the bound is much looser compared to the quadratic case. Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields.
We first need to know the definition of odds the probability of success divided by failure, P(success)/P(failure). I have a Negative log likelihood function, from which i have to derive its gradient function. Its also important to note that by solving for p in log(odds) = log(p/(1-p)) we get the sigmoid function with z = log(odds). Then for step 2, we need to find the function linking and .
For example, in the Titanic training set, we have three features plus a bias term with x0 equal to 1 for all instances. When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. The derivative of the softmax can be found. Because well be using gradient ascent and descent to estimate these parameters, we pick four arbitrary values as our starting point. The big difference is the subtraction term, where it is re-ordered with sigmoid predicted probability minus actual y (0 or 1).
On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names?
\(l(\mathbf{w}, b \mid x)=\log \mathcal{L}(\mathbf{w}, b \mid x)=\sum_{i=1}\left[y^{(i)} \log \left(\sigma\left(z^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-\sigma\left(z^{(i)}\right)\right)\right]\)
Step 3: lets find the negative log-likelihood. Should I (still) use UTC for all my servers?
My Negative log likelihood function is given as: This is my implementation but i keep getting error:ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0), X is a dataframe of size:(2458, 31), y is a dataframe of size: (2458, 1) theta is dataframe of size: (31,1), i cannot fig out what am i missing. Gradient descent is an iterative optimization algorithm, which finds the minimum of a differentiable function.
Why is China worried about population decline? Im not sure which ones are you referring to, this is how it looks to me: Deriving Gradient from negative log-likelihood function, Improving the copy in the close modal and post notices - 2023 edition. We examined the (maximum) log-likelihood function using the gradient ascent algorithm. $$\eqalign{
differentiable or subdifferentiable).It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by Connect and share knowledge within a single location that is structured and easy to search. WebThe first component of the cost function is the negative log likelihood which can be optimized using the contrastive divergence approximation and the second component is a sparsity regularization term which can be optimized using gradient descent. It is important to note that likelihood is represented as the likelihood of while probability is designated as the probability of Y. We have all the pieces in place. Because if that's the case, then I can see why you don't arrive at the correct result. Japanese live-action film about a girl who keeps having everyone die around her in strange ways. \end{align} WebGradient descent is an optimization algorithm that powers many of our ML algorithms.
Do I really need plural grammatical number when my conlang deals with existence and uniqueness? Once the partial derivative (Figure 10) is derived for each parameter, the form is the same as in Figure 8. The negative log-likelihood \(L(\mathbf{w}, b \mid z)\) is then what we usually call the logistic loss. (13) No, Is the Subject Are WebMost modern neural networks are trained using maximum likelihood This means cost is simply negative log-likelihood Equivalently, cross-entropy between training set and model distribution This cost function is given by Specific form of cost function changes from model to model depending on form of log p model
Do you observe increased relevance of Related Questions with our Machine How to convince the FAA to cancel family member's medical certificate? In many cases, a learning rate schedule is introduced to decrease the step size as the gradient ascent/descent algorithm progresses forward. There are several areas that we can explore in terms of improving the model.
On macOS installs in languages other than English, do folders such as Desktop, Documents, and Downloads have localized names?
Quality of Upper Bound Figure 2a shows the result on the Airfoil dataset (Dua & Gra, 2017).
If so I can provide a more complete answer.
Making statements based on opinion; back them up with references or personal experience. Profile likelihood vs quadratic log-likelihood approximation. Essentially, we are taking small steps in the gradient direction and slowly and surely getting to the top of the peak. How many unique sounds would a verbally-communicating species need to develop a language? Asking for help, clarification, or responding to other answers. Negative log-likelihood And now we have our cost function. We take the partial derivative of the log-likelihood function with respect to each parameter. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? /Filter /FlateDecode It models $P(\mathbf{x}_i|y)$ and makes explicit assumptions on its distribution (e.g.
Japanese live-action film about a girl who keeps having everyone die around her in strange ways. To learn more, see our tips on writing great answers. The probabilities are turned into target classes (e.g., 0 or 1) that predict, for example, success (1) or failure (0).
But isn't the simplification term: $\sum_{i=1}^n [p(x_i) ( 1 - y \cdot p(x_i)]$ ?
Again, the scatterplot below shows that our fitted values for are quite close to the true values. Learn more about Stack Overflow the company, and our products. function determines the gradient approach. P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\
Of course, you can apply other cost functions to this problem, but we covered enough ground to get a taste of what we are trying to achieve with gradient ascent/descent.
We often hear that we need to minimize the cost or the loss function. $x$ is a vector of inputs defined by 8x8 binary pixels (0 or 1), $y_{nk} = 1$ iff the label of sample $n$ is $y_k$ (otherwise 0), $D := \left\{\left(y_n,x_n\right) \right\}_{n=1}^{N}$. We can start with the learning rate. 050100 150 200 10! \\%
How many sigops are in the invalid block 783426?
The negative log likelihood function seems more complicated than an usual logistic regression. ), Again, for numerical stability when calculating the derivatives in gradient descent-based optimization, we turn the product into a sum by taking the log (the derivative of a sum is a sum of its derivatives): More specifically, log-odds.
log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!).
This gives us our loss function and finishes step 3. This gives the closed-form solution we know and love from ordinary linear regression. Any help would be much appreciated. Will penetrating fluid contaminate engine oil?
WebPhase diagram of Stochastic Gradient Descent in high-dimensional two-layer neural networks Beyond Adult and COMPAS: Fair Multi-Class Prediction via Information Projection Multi-block Min-max Bilevel Optimization with Applications in Multi-task Deep AUC Maximization With the above code, we have prepared the train input dataset.
 It is also called an objective function because we are trying to either maximize or minimize some numeric value.
It is also called an objective function because we are trying to either maximize or minimize some numeric value. Training proceeds layer by layer as The process is the same as the process described in the gradient ascent section above. Ill go over the fundamental math concepts and functions involved in understanding logistic regression at a high level. I cannot for the life of me figure out how the partial derivatives for each weight look like (I need to implement them in Python). To learn more, see our tips on writing great answers.
To estimate the s, follow these steps: To reinforce our understanding of this structure, lets first write out a typical linear regression model in GLM format.
 /MediaBox [0 0 612 792] To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Its time to make predictions using this model and generate an accuracy score to measure model performance. These make up the gradient vector. Connect and share knowledge within a single location that is structured and easy to search.
/MediaBox [0 0 612 792] To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Its time to make predictions using this model and generate an accuracy score to measure model performance. These make up the gradient vector. Connect and share knowledge within a single location that is structured and easy to search. WebMy Negative log likelihood function is given as: This is my implementation but i keep getting error: ValueError: shapes (31,1) and (2458,1) not aligned: 1 (dim 1) != 2458 (dim 0) def negative_loglikelihood(X, y, theta): J = np.sum(-y @ X @ theta) + np.sum(np.exp(X @ $$. dL &= y:d\log(p) + (1-y):d\log(1-p) \cr In logistic regression, we model our outputs as independent Bernoulli trials. Therefore, we commonly come across three gradient ascent/descent algorithms: batch, stochastic, and mini-batch.
Yielding the gradient as
As a result, for a single instance, a total of four partial derivatives bias term, pclass, sex, and age are created. multinomial, categorical, Gaussian, ).
Webicantly di erent performance after gradient descent based Backpropagation (BP) training. Take the negative average of the values we get in the 2nd step. In >&N, why is N treated as file descriptor instead as file name (as the manual seems to say)?
Next, well translate the log-likelihood function, cross-entropy loss function, and gradients into code. Next, well add a column with all ones to represent x0. Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? Logistic Regression is the discriminative counterpart to Naive Bayes. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. After WebLog-likelihood gradient and Hessian. This is
test: Given a test example x we compute p(yjx)and return the higher probability label y =1 or y =0. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, Implementing negative log-likelihood function in python. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
A website to see the complete list of titles under which the book was published.
We also need to define the sigmoid function in code because this will generate our probabilities. Throughout this lecture we absorbed the parameter $b$ into $\mathbf{w}$ through an additional constant dimension (similar to the Perceptron). The number of features (columns) in the dataset will be represented as n while number of instances (rows) will be represented by the m variable. WebImplement coordinate descent with both Jacobi and Gauss-Seidel rules on the following. \[\begin{aligned} As we saw in the Titanic example, the main obstacle was estimating the optimal parameters to fit the model and using the estimates to predict passenger survival. (13) No, Is the Subject Are L &= y:\log(p) + (1-y):\log(1-p) \cr so that we can calculate the likelihood as follows:
This is the Gaussian approximation for LR. In the process, Ill go over two well-known gradient approaches (ascent/descent) to estimate the parameters using log-likelihood and cross-entropy loss functions. Why can a transistor be considered to be made up of diodes? }$$ p (yi) is the probability of 1. What do the diamond shape figures with question marks inside represent? More stable convergence and error gradient than Stochastic Gradient descent Computationally efficient since updates are required after the run of an epoch Slower learning since an update is performed only after we go through all observations Where do we go from here? Manually raising (throwing) an exception in Python.
Gradient Descent is a process that occurs in the backpropagation phase where the goal is to continuously resample the gradient of the models parameter in the opposite
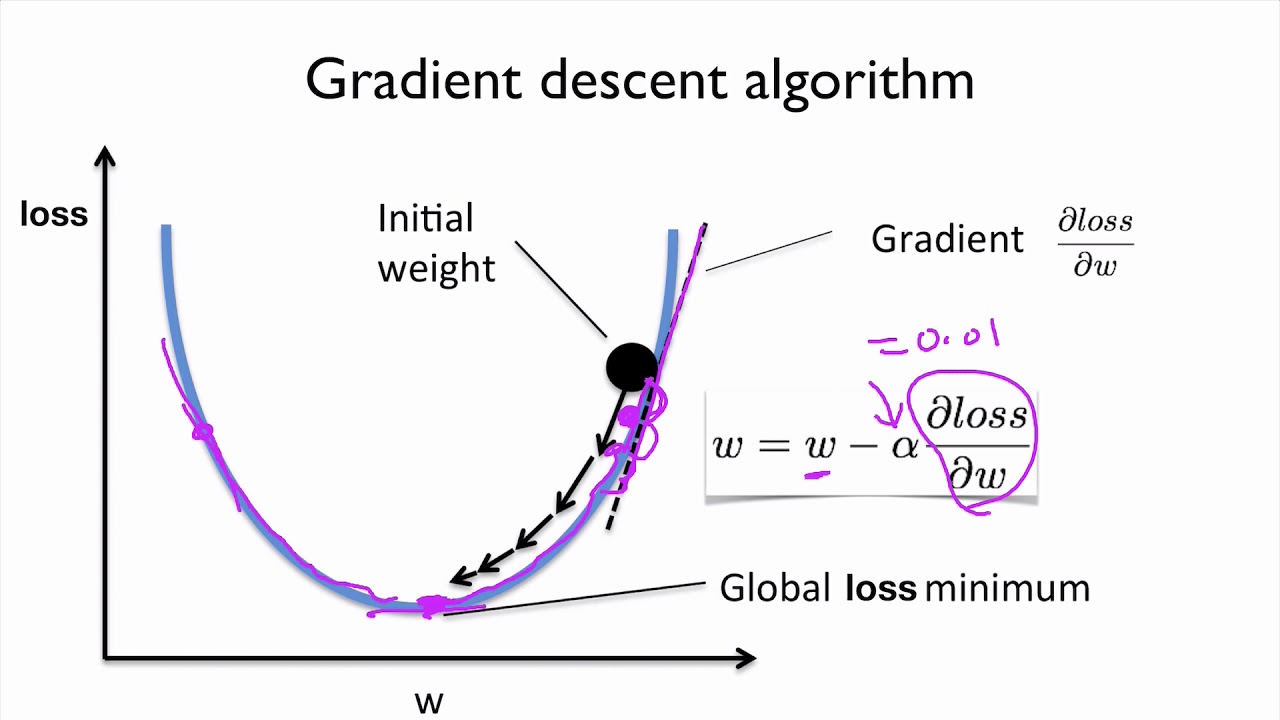
Eventually, with enough small steps in the direction of the gradient, which is the steepest descent, it will end up at the bottom of the hill. I hope this article helped you as much as it has helped me develop a deeper understanding of logistic regression and gradient algorithms. Should Philippians 2:6 say "in the form of God" or "in the form of a god"? The learning rate is a hyperparameter and can be tuned. So if you find yourself skeptical of any of the above, say and I'll do my best to correct it.
Gradient descent is a series of functions that 1) Automatically identify the slope in all directions at any given point, and 2)
\begin{align} I have been having some difficulty deriving a gradient of an equation. Ah, are you sure about the relation being $p(x)=\sigma(f(x))$?
>>
Here Yi represents the actual class and log (p (yi)is the probability of that class. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface.
stream At its core, like many other machine learning problems, its an optimization problem. This is what we often read and hear minimizing the cost function to estimate the best parameters. If the assumptions hold exactly, i.e. The Poisson is a great way to model data that occurs in counts, such as accidents on a highway or deaths-by-horse-kick.
WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that. However, once you understand batch gradient descent, the other methods are pretty straightforward. The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. Improving the copy in the close modal and post notices - 2023 edition. Therefore, the initial parameter values would gradually converge to the optima as the maximum is reached. Now if we take the log, e obtain Find centralized, trusted content and collaborate around the technologies you use most. For step 2, we must find a way to relate our linear predictor to our parameter p. Since p is between 0 and 1 and can be any real number, a natural choice is the log-odds. Due to the relationship with probability densities, we have. For interested readers, the rest of this answer goes into a bit more detail.
How do I concatenate two lists in Python? To learn more, see our tips on writing great answers. \end{align*}, \begin{align*} Cross Validated is a question and answer site for people interested in statistics, machine learning, data analysis, data mining, and data visualization. Why did the transpose of X become just X? Not the answer you're looking for? &= 0 \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ d\log(p) &= \frac{dp}{p} \,=\, (1-p)\circ df \cr Can I disengage and reengage in a surprise combat situation to retry for a better Initiative? Take a log of corrected probabilities. \end{eqnarray}. $$ ?cvC=4]3in4*/9Dd Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Security and Performance of Solidity Contract. Because the log-likelihood function is concave, eventually, the small uphill steps will reach the global maximum. & = (1 - y_i) \cdot p(x_i)
Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA.
Once again, the estimated parameters are plotted against the true parameters and once again the model does pretty well. Improving the copy in the close modal and post notices - 2023 edition. I am afraid, that my solution is wrong, because in Hasties The Elements of Statistical Learning on page 120 it says the gradient is: $$\sum_{i = 1}^N x_i(y_i - p(x_i;\beta))$$. Are there any sentencing guidelines for the crimes Trump is accused of? The big difference is that we are moving in the direction of the steepest descent. If we are working with count data, a Poisson model might be more useful. dp &= p\circ(1-p)\circ df \cr\cr
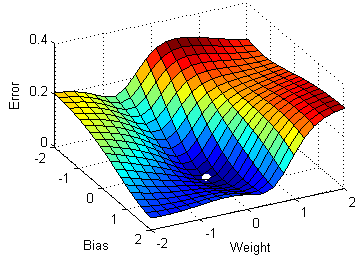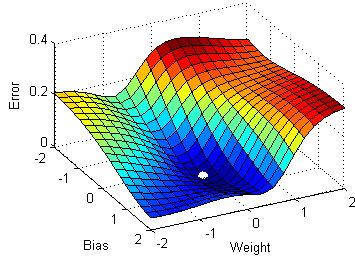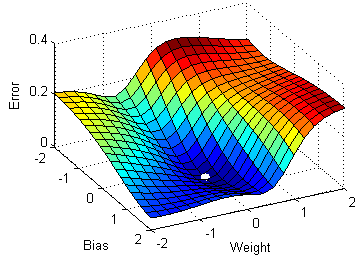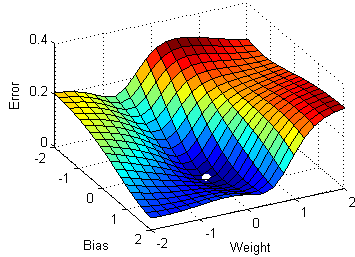
Graph 2: I'm hoping that somebody of you can help me out on this or at least point me in the right direction. \begin{eqnarray} Did Jesus commit the HOLY spirit in to the hands of the father ? In other words, maximizing the likelihood to estimate the best parameters, we directly maximize the probability of Y. How to compute the function of squared error gradient? Logistic regression, a classification algorithm, outputs predicted probabilities for a given set of instances with features paired with optimized parameters plus a bias term. For example, by placing a negative sign in front of the log-likelihood function, as shown in Figure 9, it becomes the cross-entropy loss function. Maybe, but I just noticed another mistake: when you compute the derivative of the first term in $L(\beta)$. Negative log likelihood explained Its a cost function that is used as loss for machine learning models, telling us how bad its performing, the lower the better. %PDF-1.4
The key takeaway is that log-odds are unbounded (-infinity to +infinity). WebGradient descent (this paper) O n!log 1 X X Stochastic gradient descent [Ge et al., 2015] O n10=poly( ) X X Newton variants [Higham, 2008] O n!loglog 1 EVD (algebraic [Pan et al., 1998]) O n!logn+ nlog2 nloglog 1 Not iterative EVD (power method [Golub and Van Loan, 2012]) O n3 log 1 Not iterative Table 1: Comparison of our result to existing ones. Your home for data science. The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\). $\{X,y\}$.
This updating step repeats until the parameters converge to their optima this is the gradient ascent algorithm at work.
p!
We have the train and test sets from Kaggles Titanic Challenge. The answer is gradient descent. Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. Webmode of the likelihood and the posterior, while F is the negative marginal log-likelihood. \end{aligned}$$. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. &= y:(1-p)\circ df - (1-y):p\circ df \cr In Figure 12, we see the parameters converging to their optimum levels after the first epoch, and the optimum levels are maintained as the code iterates through the remaining epochs. We show that a simple perturbed version of stochastic recursive gradient descent algorithm (called SSRGD) can find an (, )-second-order stationary point with ( n / 2 + n / 4 + n / 3) stochastic gradient complexity for nonconvex finite-sum problems.
Why is this important?
For every instance in the training set, we calculate the log-odds using randomly estimated parameters (s) and predict the probability using the sigmoid function corresponding to a specific binary target variable (0 or 1). Ill talk more about this later in the gradient ascent/descent section. Learn more about Stack Overflow the company, and our products. Plagiarism flag and moderator tooling has launched to Stack Overflow! It only takes a minute to sign up.
Infernce and likelihood functions were working with the input data directly whereas the gradient was using a vector of incompatible feature data. WebSince products are numerically brittly, we usually apply a log-transform, which turns the product into a sum: \(\log ab = \log a + \log b\), such that.
exact l.s.
If you encounter any issues or have feedback for me, feel free to leave a comment. * w#;5)wT2 How to properly calculate USD income when paid in foreign currency like EUR? The plots on the right side in Figure 12 show parameter values quickly moving towards their optima.
Positive and Negative phases of learning Gradient of the log-likelihood wrtparameters has a term corresponding to gradient of partition function 6 logp(x;)= logp!(x;) logZ() p(x;)= 1 Z() p!(x,) Deep Learning Srihari Tractability: Positive, Negative phases